
Vi bringer her RettighedsAlliancens debatindlæg, som er udgivet hos Teknologiens mediehus’ medie Datatech tirsdag den 14. november 2023. Debatindlægget kan læses her.
I udviklingen af kunstig intelligens er kreativt indhold blevet eneftertragtet kilde til træningsdata. Vi gør klogt i at lære af fortiden, nu hvor ophavsretten atter rammesættes som teknologiens fjende.
Udviklingen af kunstig intelligens møder fascination i hele verden, ikke mindst blandt kunstnere, der omfavner de nye værktøjer. Samtidig oplever skaberne af kreativt indhold at de mister muligheden for at kontrollere brugen af deres værker, fordi menneskeskabt kvalitetsindhold er blevet en eftertragtet kilde til træningsdata hos udviklerne af generativ kunstig intelligens.
RettighedsAlliancens nedtagninger af det ulovlige træningsdatasæt Books3 har fået stor opmærksomhed i offentligheden. Det har også avlet modstand iblandt udviklere af kunstig intelligens, der viderefører de samme forestillinger, som drev udviklingen af det ulovlige fildelingsmiljø i starten af 00’erne. Men forestillingen om, at ophavsrettigheder begrænser ytringsfriheden og udviklingen af et digitaliseret demokratisk samfund, tjener kun dem, som profiterer på brugen af ulovligt indhold.
I teknologiens tjeneste
Med den hastige udvikling indenfor kunstig intelligens er billeder, tekst, musik og andet kreativt indhold blevet eftertragtede data til træning af f.eks. sprogmodeller og billedgenereringsprogrammer. For eksempel beskrives bøger som en uundværlig kilde til træningsdata af organisationen EleutherAI, som står bag udgivelsen af træningsdatasættet Books3: »We included [books3] because books are invaluable for long-range context modeling research and coherent storytelling.«
Det forholder sig dog sådan, at Books3 er ulovligt, da datasættet indeholder ca. 200.000 e-bøger, som er hentet fra en ulovlig tysk fildelingstjeneste. Efter at have identificeret ulovlige kopier af danske værker i datasættet, lykkedes det os i RettighedsAlliancen at få fjernet Books3 fra udgiveren EleutherAI og andre kroge af internettet. En bedrift, der har vakt opsigt i medier og blandt rettighedshavere i hele verden, da det er første gang, et ulovligt træningsdatasæt bliver nedtaget som led i håndhævelse af rettigheder.
Men nedtagningen af Books3 møder også modstand fra blandt andre udviklere, som mener, at håndhævelse af ophavsretten sætter en kæp i hjulet på et uundgåeligt teknologisk fremskridt eller ligefrem »ødelægger verden« ifølge reaktionerne på X:
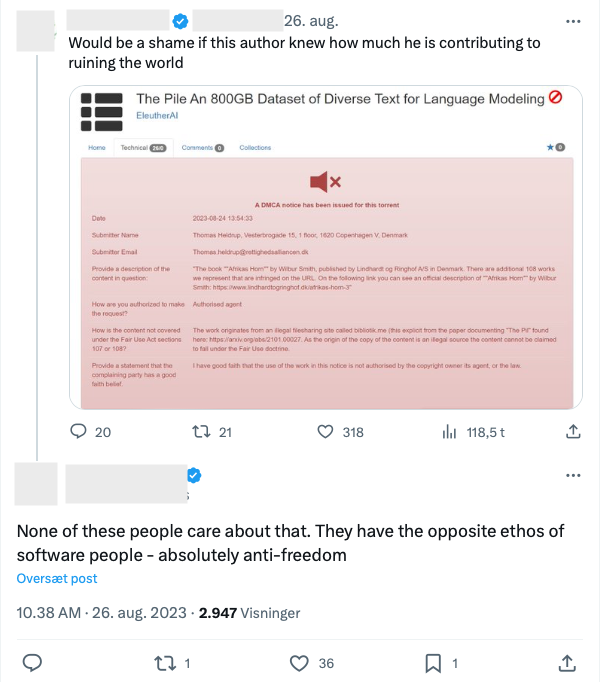
Det er et udtryk for, at anvendelsen af ulovligt indhold i træningen af kunstig intelligens, begrundes med de samme synspunkter, som drev det ulovlige fildelingsmiljø: at den enkeltes ret til at kopiere, dele og anvende indhold er en forudsætning for ytringsfrihed og demokrati i den digitale tidsalder.
Ved udbredelsen af internettet fik det ulovlige fildelingsmiljø et gunstigt forspring, idet paroler som ’information wants to be free’ medførte, at politikere og myndigheder for en tid nægtede, at internettet skulle reguleres. Et eksempel herpå er modstanden mod ACTA-traktaten i 2012, hvor håndhævelse af ophavsretten blev rammesat som demokratiets fjende.
I samme stil mener Shawn Presser, udvikleren bag Books3-datasættet, at brugen af kreativt indhold i træningsdata er en forudsætning for, at udviklingen af kunstig intelligens udbredes:
»[I]t’s crucial that you and I can make our own ChatGPTs, for the same reason it was crucial that anybody could make their own website back in the ‘90s. […] The only way to replicate models like ChatGPT is to create datasets like Books3. And every for-profit company does this secretly, without releasing the datasets to the public.«
Mens det er korrekt, at tech-giganter ikke er transparente omkring deres brug af data, forholder det sig sådan, at både Meta, StabilityAI og Bloomberg alle har anvendt Books3 i træningen af tidligere versioner af deres modeller. Det klinger derfor hult, at ulovlige datasæt som Books3 skal demokratisere udviklingen af kunstig intelligens, når selvsamme data har trænet verdens førende AI-tjenester.
Piratkopiering er således ikke længere et spørgsmål om den enkeltes brug og deling af ulovligt indhold, men kan derimod tilskrives en del af succesen bag generative AI-tjenester, udviklet af verdens mest indbringende virksomheder:
»A culture of piracy has existed since the early days of the internet, and in a sense, AI developers are doing something that’s come to seem natural. It is uncomfortably apt that today’s flagship technology is powered by mass theft.«
Målet helliger ikke midlet
Det er paradoksalt, at kunstig intelligens afhænger af menneskeskabt kvalitetsindhold, når brugen af selv samme i træningen af tjenesterne, udvander den kreative branche. Først ved at misbruge indholdet, og dernæst ved at generere nyt indhold, som konkurrerer imod rettighedshavernes produkter. Det risikerer at føre til en nedadgående spiral, hvor udbuddet af kreativt indhold forringes gradvist som en konsekvens af, at kreative aktører mister kontrollen over deres indhold, og dermed indtjeningsgrundlaget under det. Yderligere risikerer vi, at kvaliteten af kreativt indhold daler, hvis fremtidens kulturindhold snarere er skabt af maskiner end mennesker. Det vil ikke alene gøre kunstnere, men hele verden fattigere.
Rettighedshavernes mulighed for at kontrollere brugen af deres indhold forudsætter transparens hos udviklerne af kunstig intelligens. Nedtagningen af Books3 understreger dette, da datasættet undtagelsesvist indeholdt information om indholdet og kilden bag de respektive data. Men udviklerne af kunstig intelligens tjenester skjuler i stigende grad, hvilke data der har trænet deres modeller. For eksempel stiller Meta ikke information om træningsdata til rådighed i den seneste version af deres AI-tjeneste LLaMA-2, i modsætning til LLaMA-1, hvor de anvendte træningsdata, herunder Books3, fremgår. Uden krav om transparens, betinges rettighedshaveres mulighed for at sikre deres indhold af den frie vilje hos de tech-virksomheder, som er dybt afhængige af kvalitetsindhold for at komme først i AI-kapløbet.
Hvis kreativt indhold skal anvendes til træning af kunstig intelligens, skal dette, i modsætning til historikken med fildelingstjenester, ske med respekt for de aktører, som beriger verden med kunst – og værdifulde træningsdata. Det kræver, at vi afliver myten om, at ophavsrettigheder spænder ben for teknologiens fremskridt og den enkeltes frihed. Erfaringerne med bekæmpelsen af ulovlig fildeling viser, at det er et synspunkt, som kun gavner dem, der profiterer på at træne AI-tjenester med ulovligt indhold.